1问题描述:
数据库版本05134284368-20250430-272000-20149
增加备份作业,报错报错-3503 无效的函数参数
经过检查发现,为新增作业调度出错
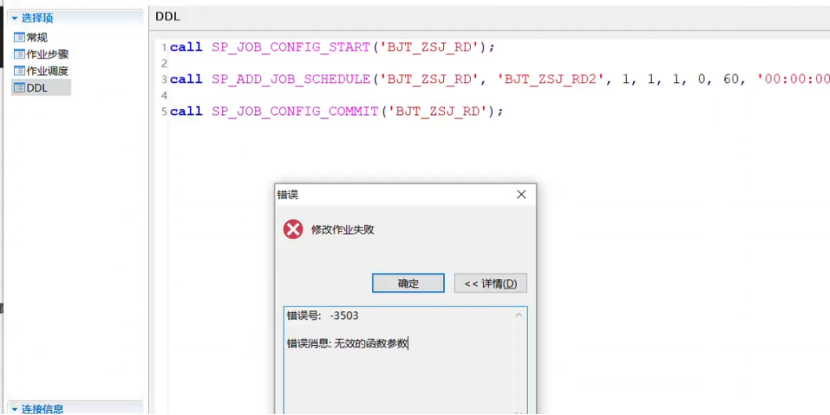
2问题原因:
检查客户配置发现配置了
select para_value from v$dm_ini where para_name='COMPATIBLE_MODE';
结果为4 --兼容MYSQL
本地测试复现问题
创建作业系统表
SP_INIT_JOB_SYS(1);
全量备份(每周六 23 点全备):其中有1分钟后的一次性全备调度,执行完成后检查备份是否成功。
call SP_CREATE_JOB('bakfull',1,0,'',0,0,'',0,'');
call SP_JOB_CONFIG_START('bakfull');
call SP_ADD_JOB_STEP('bakfull', 'bak01', 6, '00000000/db_bak/dmbak/ip4.43', 0, 0, 0, 0, NULL, 0);
call SP_ADD_JOB_SCHEDULE('bakfull', 'std1', 1, 2, 1, 64, 0, '23:00:00', NULL, '2021-10-22 14:24:06', NULL, '');
call SP_ADD_JOB_SCHEDULE('bakfull', 'once1', 1, 0, 0, 0, 0, NULL, NULL, sysdate+1/1440, NULL, '');
call SP_JOB_CONFIG_COMMIT('bakfull');
增量备份(每周除周六外每天 23 点增量备份):
call SP_CREATE_JOB('bakincr',1,0,'',0,0,'',0,'');
call SP_JOB_CONFIG_START('bakincr');
call SP_ADD_JOB_STEP('bakincr', 'bak2', 6, '40000000/db_bak/dmbak/ip4.43|/db_bak/dmbak/ip4.43', 0, 0, 0, 0, NULL, 0);
call SP_ADD_JOB_SCHEDULE('bakincr', 'std2', 1, 2, 1, 63, 0, '23:00:00', NULL, '2021-10-22 14:24:06', NULL, '');
call SP_JOB_CONFIG_COMMIT('bakincr');
备份定期删除(每天 23:30 删除 14 天前备份):
call SP_CREATE_JOB('delbak',1,0,'',0,0,'',0,'');
call SP_JOB_CONFIG_START('delbak');
call SP_ADD_JOB_STEP('delbak','bak1',0, 'SF_BAKSET_BACKUP_DIR_ADD(''DISK'',''/db_bak/dmbak/ip4.43'');
call sp_db_bakset_remove_batch(''DISK'',now()-14);', 1, 2, 0, 0, NULL, 0);
call SP_ADD_JOB_SCHEDULE('delbak', 'del01', 1, 1, 1, 0, 0, '23:30:00', NULL, '2020-11-02 14:48:41', NULL, '');
call SP_JOB_CONFIG_COMMIT('delbak');
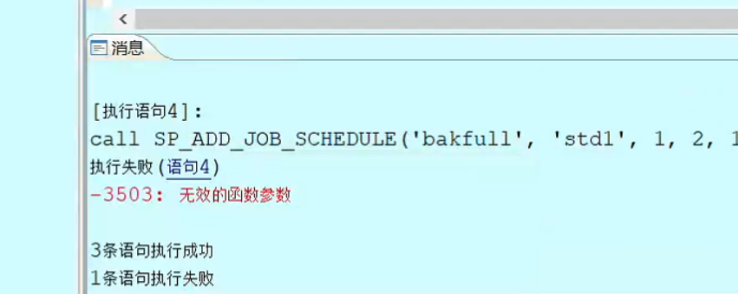
3解决方案:
开启兼容后,时间格式发生了变化导致的
可以先改成COMPATIBLE_MODE为0,重启数据库生效,创建job后再改成4,再次重启数据库参数生效
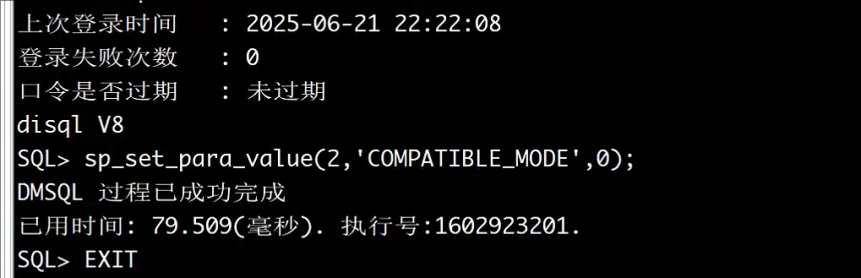
sp_set_para_value(2,'COMPATIBLE_MODE',0);
sp_set_para_value(2,'COMPATIBLE_MODE',4);