Self-Attention
- Scaled Dot-Product Attention(缩放点积注意力):
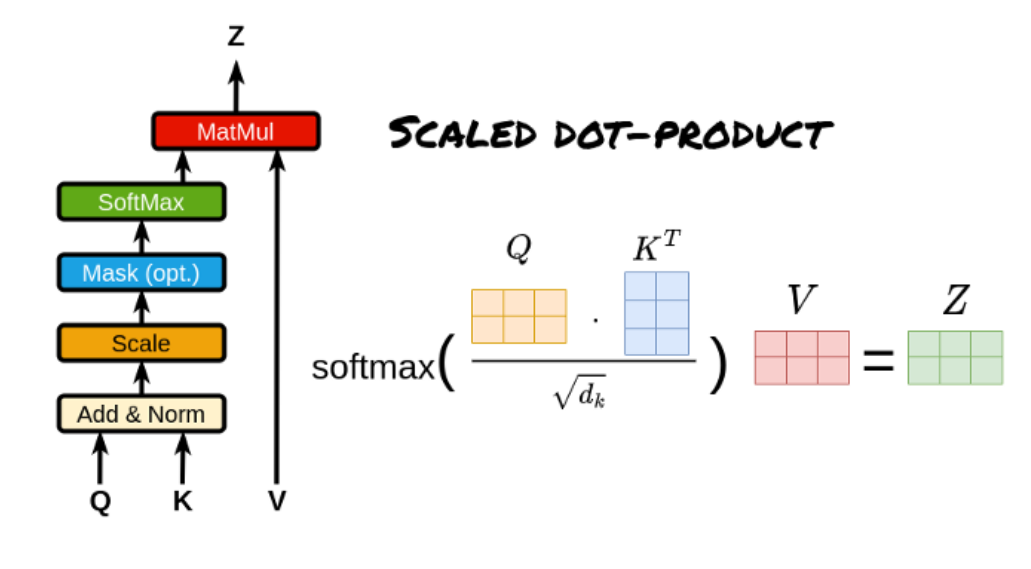
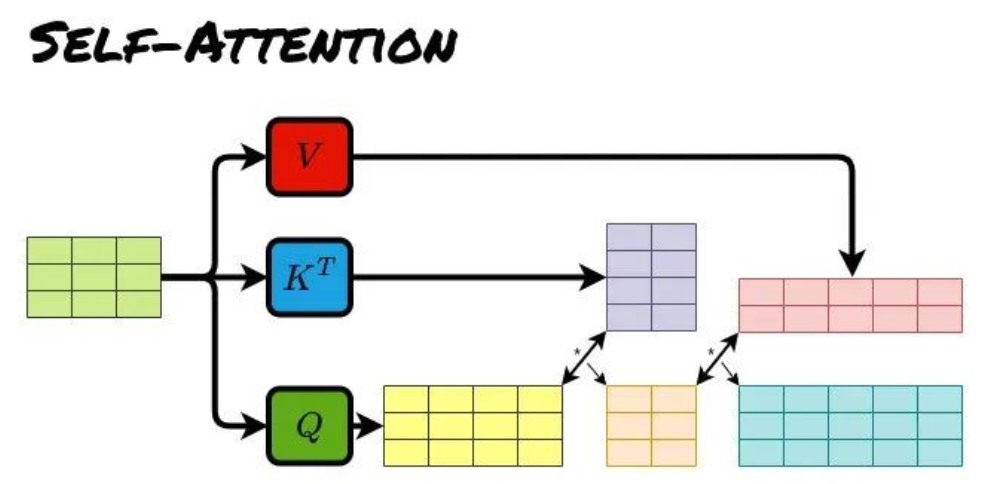
- Self-Attention允许模型在处理一个输入序列时,关注序列内部的每个元素之间的关系。每个元素既作为查询(Query),又作为键(Key)和值(Value),通过计算自身与其他元素的相关性来更新表示
Cross-Attention
- Cross-Attention用于建模两个不同序列之间的关系。一个序列提供查询(Query),另一个序列提供键(Key)和值(Value),它通常用于需要融合来自不同数据源或模态的信息的任务
- 在 Transformer解码器中,查询来自目标语言序列,键-值来自源语言序列(如将“Je t’aime”翻译为“I love you”时对齐“aime”和“love”)

原文
- https://blog.csdn.net/qq_41990294/article/details/147746522