- Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
- TL; DR;
- Data
- Stage I: Image Pretraining
- Stage II: Curating a Video Pretraining Dataset
- Stage III: High-Quality Finetuning
- Method
- Experiment
- 总结与思考
- 相关链接
- Related works中值得深挖的工作
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
link
时间:2023年11月
单位:Stability AI
相关领域:计算机视觉、视频生成、扩散模型
被引次数:300+
项目主页:
https://stability.ai/news/stable-video-diffusion-open-ai-video-model
https://huggingface.co/stabilityai/stable-video-diffusion-img2vid
TL; DR;
Stable Video Diffusion (SVD)是一个基于潜在扩散模型的文生视觉与图生视频框架,训练分为三阶段:text-to-image pretraining, video pretraining, and high-quality video finetuning。效果上与闭源的文生视频效果接近。实验证明SVD具有很好的运动表征及相机运动能力,同时该模型隐含了较强的3D先验,能够用来finetune多视频diffusion模型。
Data
Stage I: Image Pretraining
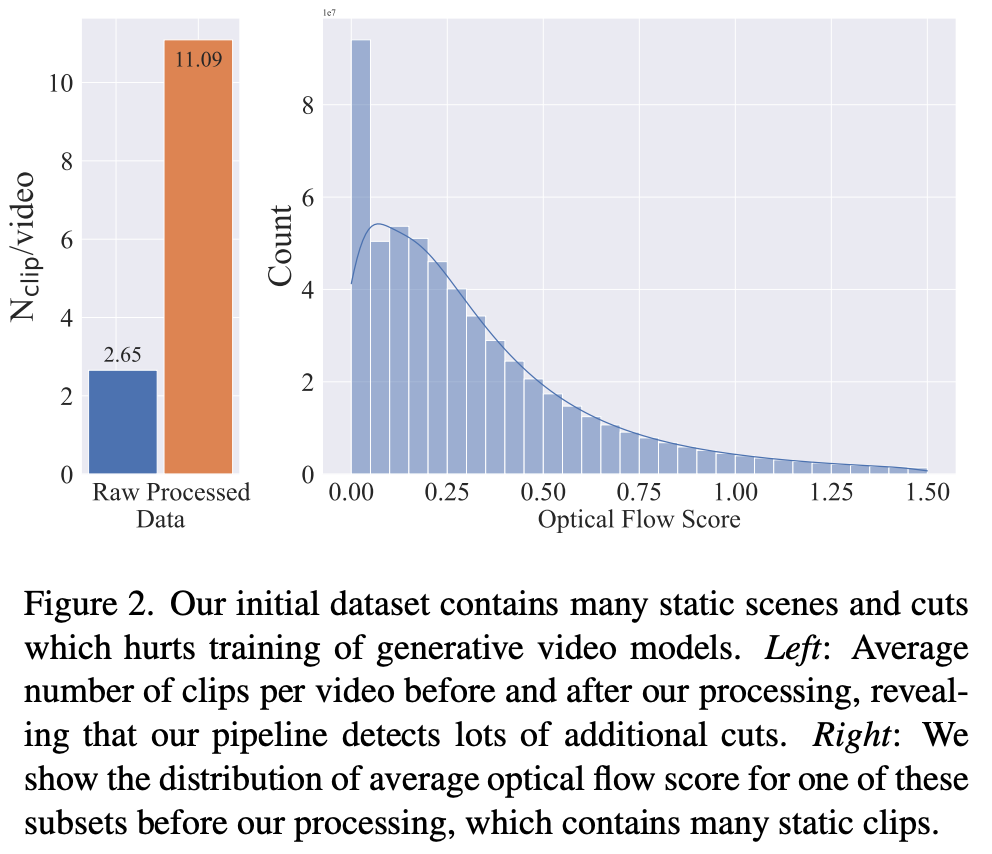
整理出LVD(Large Video Dataset)数据集, 580M组(视频clip,描述文本)样本对,制作关键步骤如下:
- 收集一些长视频
- 使用cut-detection pipeline工具将长视频切成小视频片段
- 使用V-BLIP算法获取小视频片段的文本描述
- 使用CoCa算法获取小视频片段中间帧的文本描述
- 使用LLM将上述两种文本描述进行总结
- 计算视频的平均光流将静态小视频片段进行过滤

Stage II: Curating a Video Pretraining Dataset
Stage II 的目标是通过系统化的数据筛选流程,将原始大规模视频数据集(LVD,含580M样本)优化为高质量预训练数据集(LVD-F,152M样本),以提升视频生成模型的性能。关键点包括:
- 数据质量:过滤静态场景、低美学价值或文本干扰的样本。
- 运动表征:确保视频包含有效运动,避免静态帧主导训练。
- 标注多样性:通过多模态合成标注增强文本-视频对齐。
Stage III: High-Quality Finetuning
使用250K pre-captioned video clips of high visual fidelity来Finetune上个阶段的模型。
Method
由于本文重在讲解数据构造,算法架构复用前人工作:
(1) Stage I: Image Pretraining
核心架构:SD 2.1的UNet + VAE(Latent Diffusion)。
推荐论文:
High-Resolution Image Synthesis with Latent Diffusion Models (Rombach et al.)
重点阅读:Section 3(Architecture)和Figure 2(UNet示意图)。
(2) Stage II: Video Pretraining
核心架构:SD 2.1 + 时序层插入(3D卷积/注意力)。
推荐论文:
Align Your Latents (Blattmann et al.),引用量1345
重点阅读:Section 3(Temporal Layer Design)和Figure 3(架构对比)。
Video Diffusion Models (Ho et al.),引用量2070
重点阅读:Section 4(Temporal Adaptation)。
(3) Stage III: High-Quality Finetuning
核心架构:基于Stage II模型 + 分辨率提升(576×1024)。
推荐论文:
Imagen Video (Ho et al.),引用量1733
重点阅读:Section 4.2(Cascaded Diffusion for HQ Finetuning)。
SDXL: Improving Latent Diffusion Models (Podell et al.),引用量2894
重点阅读:Section 3.2(High-Resolution Training Strategies)。
Experiment
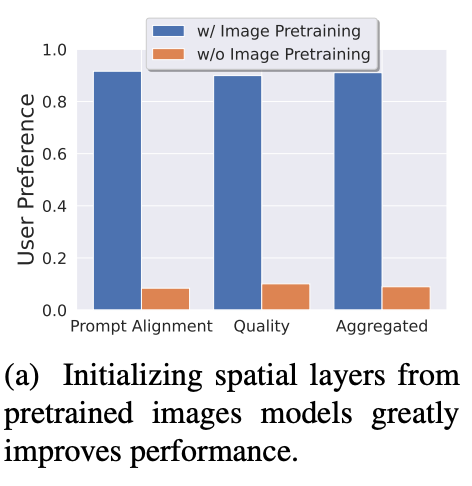
使用Stage1的Image Stable Diffusion进行预训练,该阶段对于最终效果影响还是比较明显,参考下图Figure 3a。
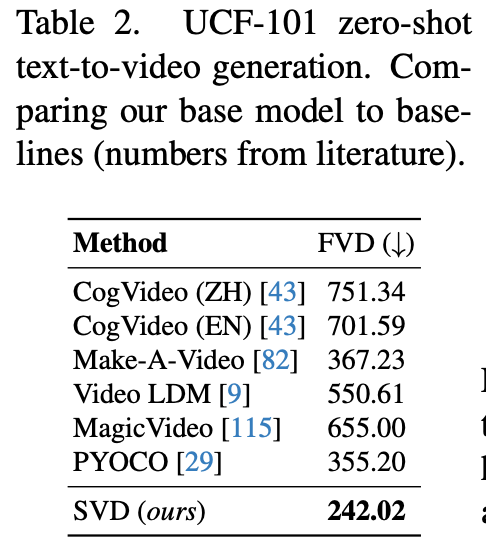
在UCF-101 zero-shot text-to-video generation超过之前方法。
SVD-MV (在多目数据上Finetune后的版本)生成的多视角图片的效果

总结与思考
无
相关链接
https://zhuanlan.zhihu.com/p/699035548
Related works中值得深挖的工作
Align Your Latents (Blattmann et al.),引用量1345
Video Diffusion Models (Ho et al.),引用量2070
Imagen Video (Ho et al.),引用量1733
SDXL: Improving Latent Diffusion Models (Podell et al.),引用量2894