分享一篇今年由河南农业大学康相涛院士团队主导的研究论文Advanced molecular system for accurate identification of chicken genetic resources。该研究成功开发了一种高效、准确的鸡种质资源分子鉴定系统,文章提出的思路和方法,可拓展应用于其他家禽家畜物种。

这篇文章的核心内容是介绍了一个用于精准鉴定鸡遗传资源的先进分子系统。该系统通过整合先进的基因组分析和机器学习方法,开发了一个高通量、准确的分子鉴定系统,以应对研究和工业应用中对可靠品种鉴定工具的迫切需求。该系统不仅能够快速、准确地鉴定鸡的遗传资源,还为鸡遗传资源的保护和可持续利用提供了有力支持。
背景知识
- • 动物遗传资源对全球粮食安全和生态平衡至关重要,尤其是鸡,作为全球数量最多的动物之一,具有约1600个独特的地方品种。
- • 传统基于形态学特征的鉴定方法存在主观性强、缺乏标准化、易出错等问题,尤其是在面对外观相似但遗传差异显著的品种时。
- • 随着全球鸡遗传资源交流的增加和外来品种的引入,准确鉴定鸡遗传资源变得愈发重要。
研究方法
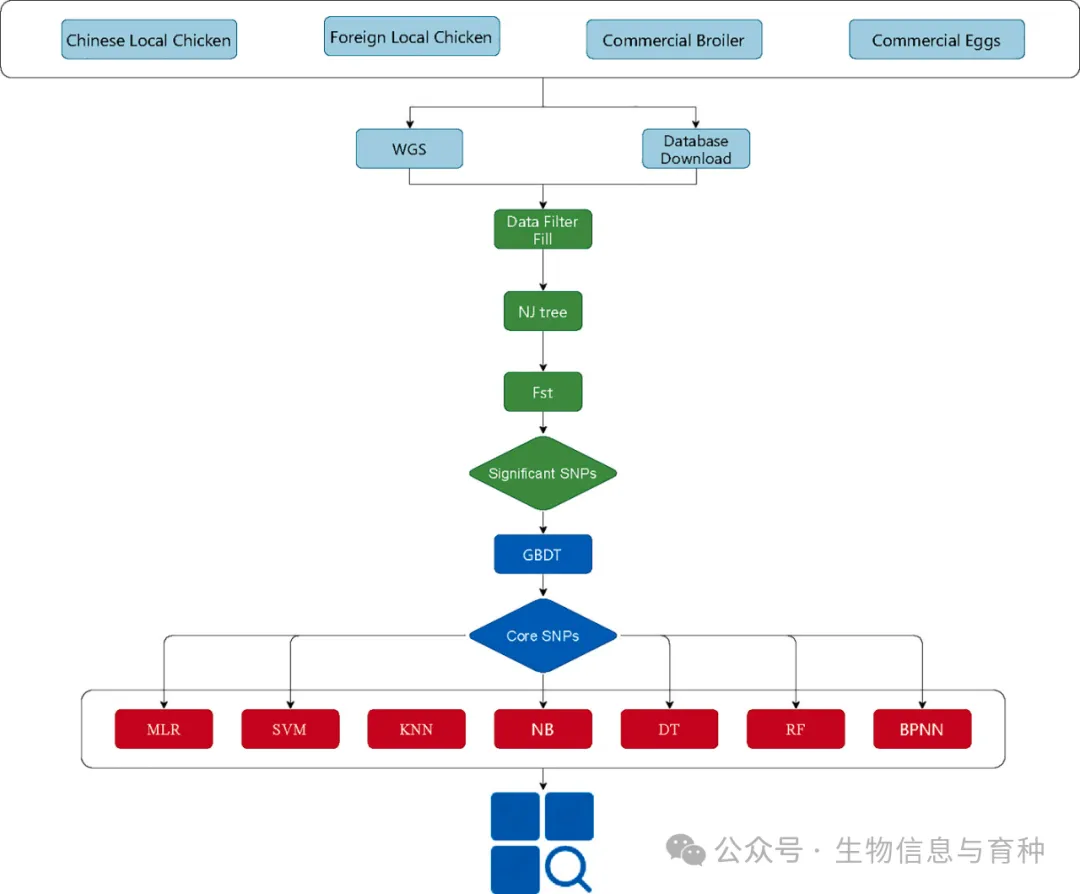
- • 样本和数据来源:研究使用了来自132个鸡遗传资源的3798个个体的全基因组重测序数据和600K芯片数据,包括40个中国地方鸡品种、3个商业肉鸡品种、2个商业蛋鸡品种和87个其他国家的地方鸡品种。
- • 基因组重测序:对110个来自6个品种的鸡进行基因组重测序,生成了1573.732 GB的原始数据,经过质量过滤后得到1566.423 GB的高质量清洁数据,共鉴定出12,162,759个SNPs。
- • 数据转换与合并:将微阵列数据与全基因组重测序数据合并,使用Plink软件进行数据合并,使用vcftools过滤缺失率大于0.1的位点,并使用Beagle软件填补缺失的基因型数据。
- • 样本筛选:通过最大似然系统发育树分析,排除了190个异常样本,最终保留了来自127个品种的3608个个体的数据。
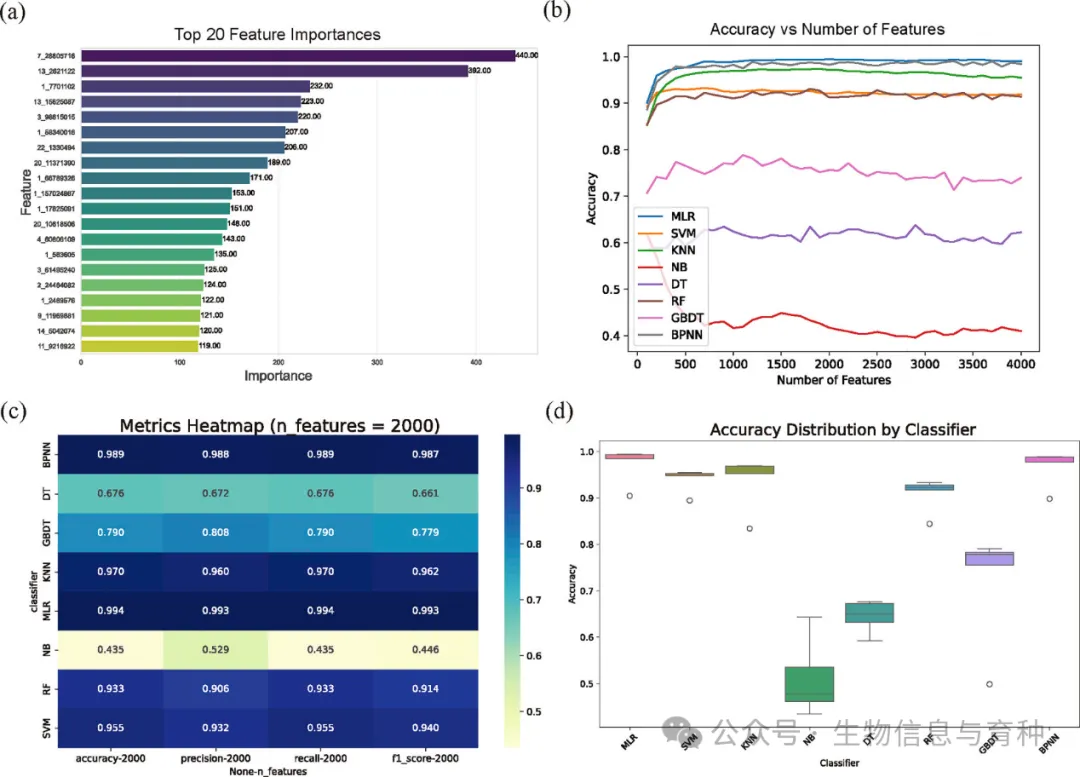
- • 特异性SNPs筛选:计算每个品种相对于其他群体的遗传分化指数(Fst),提取每个群体Fst值最高的100个位点,最终得到9733个SNPs用于机器学习算法的品种鉴定。进一步通过梯度提升决策树(GBDT)模型筛选出4000个核心位点用于建模。
- • 机器学习模型建立:使用Python语言和相关库(如pandas、numpy、scikit-learn等)开发机器学习模型,采用LightGBM进行特征重要性评分,并使用SelectFromModel进行最终特征选择。共使用了8种机器学习分类方法构建训练模型,包括多项逻辑回归(MLR)、支持向量机(SVM)、K最近邻(KNN)、朴素贝叶斯(NB)、决策树(DT)、随机森林(RF)、BP神经网络(BPNN)和梯度提升决策树(GBDT)。
- • 模型准确性评估:采用随机分层抽样和10折交叉验证策略,使用准确率、精确率、召回率和F1分数四个指标评估模型性能。
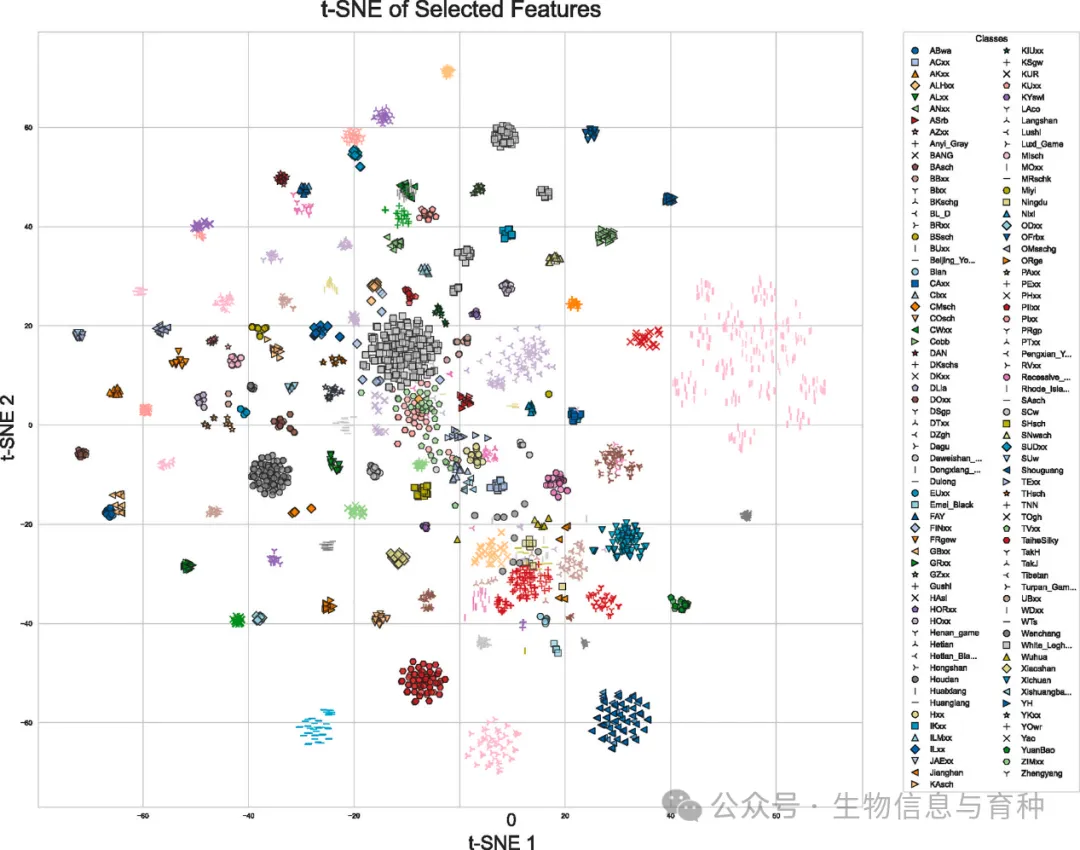
- • 鉴定系统可视化:利用t-SNE方法对MLR方法筛选的2000个SNP进行品种鉴定结果可视化。
![]()
关键结论
- • 模型性能:MLR模型在使用2000个SNPs时表现最佳,准确率达到99.45%,精确率为99.34%,召回率为99.45%,F1分数为99.34%。
- • SNPs分布:2000个SNPs主要分布在1到28号染色体上,其中1号染色体包含259个SNPs,2号染色体包含148个SNPs,16号染色体仅包含1个SNP。
- • 功能注释:通过SNPeff软件对2000个SNPs进行注释,发现内含子变异最为常见,占55.45%,其次是基因间区域(20.25%)和基因上游/下游区域(18.50%)。这些SNPs涉及的基因在分子功能、细胞结构和生物过程中具有重要作用,例如蛋白质结合、催化活性、转运活性等。
- • 系统开发:基于Flask框架开发了一个基于Web的鸡遗传资源分子鉴定系统(https://www.chickenbreeds.cn/),用户可以通过上传vcf或gvcf文件进行鸡遗传资源的鉴定。该系统还提供了数据上传功能,允许用户上传新的品种数据以扩展数据库。
![]()
![]()
研究意义
- • 该系统提供了一个快速、准确且成本效益高的鸡遗传资源鉴定方法,有助于保护和创新利用鸡遗传资源,支持家禽产业的可持续发展。
- • 该系统不仅为鸡遗传资源的保护和利用提供了有力工具,还为其他物种的分子鉴定提供了方法学框架。